
Code coverage is a software testing metric that measures the degree to which the source code of a program is tested by a particular test suite. This metrics is often difficult to understand and interpret for software development teams. In this article, Eran Sher proposes a better approach to code coverage that is more adapted to the current situation of continuous delivery and service architecture.
Author: Eran Sher, SeaLights, https://www.sealights.io/
Technically, the term coverage relates to code coverage and is normally applied to unit tests. In reality, quality assurance (QA) teams emphasize two additional coverage metrics:
* Functional coverage, as a percent of a feature/ requirement.
* Test coverage, pass, fail and skip (a more apt name for this would be execution status).
These interpretations of coverage are important and add value to understanding risk and quality. However, they are painfully out of sync with Continuous Delivery in general, and specifically out of sync with the evolving role of QA departments.
With Continuous Delivery becoming a de facto standard, testing is changing fundamentally. As we shift from the manual to the automated, the makeup of QA departments is evolving from massive, distributed teams of testers with little or no technical skills to small, focused teams of engineer/ developer testers. This new breed of tester brings with him an architect’s perspective and is focused no more on the execution of tests but on their automation. QA teams are now made up of developer testers, and they need metrics that help them build and maintain effective and efficient tests. To that end, code coverage needs to become more than what it is.
Going Beyond the Unit Test
While companies write all types of tests, code coverage has been applicable to unit tests exclusively. As tests that cover the atomic level of your code, they are the easiest tests to create and therefore it is considered a best practice that a significant proportion of your application test be unit tests. There are a variety of tools such as Sonar, JaCoCo, Istanbul and others, with which unit test coverage can be easily understood, and overall unit test code coverage is considered a resolved issue.
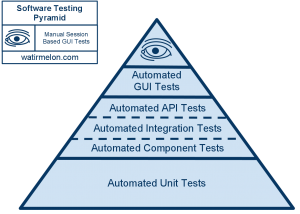
As a rule, unit tests will always comprise a significant portion of the Software Testing Pyramid, but as we move forward, their proportional impact on quality will decrease due to two factors, increasingly frequent release cycles and modern software architecture. As we release faster the pressures of automation fall more to the shoulders of API, integration, system, etc., tests as they are now critical points of failure within software release. Furthermore, the farther we progress with API architecture, the more our applications functionality depends on external services that are impossible to test in unit tests.
High-level automated tests are a critical point of failure, so a new definition of code coverage is required to help QA teams deal with the challenges that they now face. To do so, you need not only to re-implement code coverage to cover higher levels of the Software Testing Pyramid, but you also need to invert it to understand what is not covered.
Heads: Code Coverage
In Continuous Delivery, code is shipped fast and incrementally. To facilitate the need for speed, a lot of automated tests run in short periods of time. While all this is done to achieve speed, there is no baked in way to understand quality achievements and risks. Without integration/ API/ functional code coverage, test automation is implemented according to subjective need. There is no way to identify effectiveness, duplication and overlaps and there is no promise that what your automation is covering today will be what it is covering a month down the road. To make matters worse, there is no way to uncover code coverage on a product level. Overall, is your code coverage better or worse? Do you even know what your holistic coverage is?
Tails: Quality Holes
Quality Holes refer to untested code changes. It does not apply to uncovered code areas in general but specifically to recent areas of code changes that are not covered. This distinction is made because usually code changes are the result of bugs or user requirements. As such, they are areas of high exposure risk and are the last places where you want your code to break.
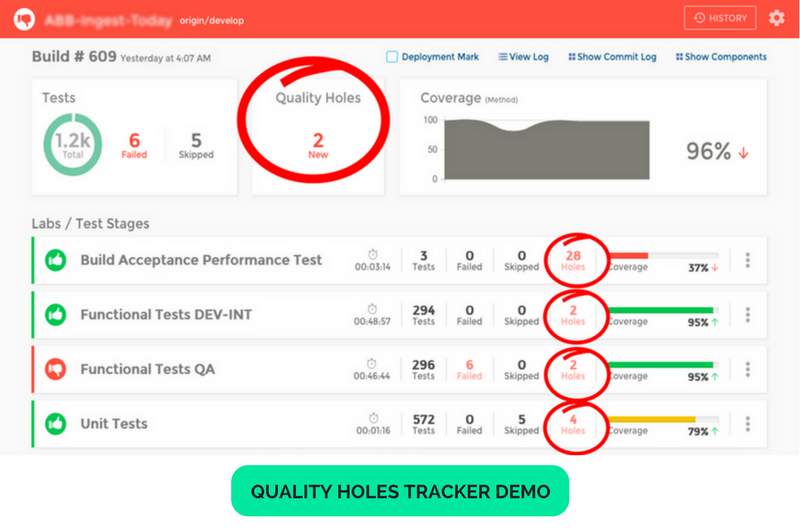
With Quality Holes as an inverted metric of code coverage we fail faster and identify high-risk code that requires tests as they are committed.
Code Coverage 2.0
The best way to achieve sophisticated code coverage is to look at it as a 3D OLAP cube for quality measurement:
Within your application solution, for each test type level:
* Check test execution status (skipped/ failed/ passed)
* Monitor level specific coverage increases/ decreases
* Flag Quality Holes

Applying this approach to each level of the Software Testing Pyramid will provide improved proofing. Though not bulletproof, it will decrease risk substantially by enabling faster exposure of bugs and critical points of failure at each and every cycle.
As with all good OLAP cubes, you can customize the quality metrics view to gain even more insights regarding holistic coverage of your entire test suite (consisting of all its services) or any test type subset derived from it (e.g. combined coverage of both integration and end-to-end tests). These metrics will provide you with the knowledge you’ll need going forward with product development in short cycles while maintaining quality.
Effective and Efficient Tests
One of the upsides to modern code coverage is not only new metrics into functional test code coverage and Quality Holes, but how this data can be used to plan effective and efficient test automation. As mentioned previously, planning test automation is largely subjective and always about speed, not quality. Now, with multifaceted code coverage and Quality Holes, it is possible to invest in test automation objectively based on immediacy, relevancy, and risk.
Let’s take a look at SeaLight’s interactive demo and see we identify where to invest:
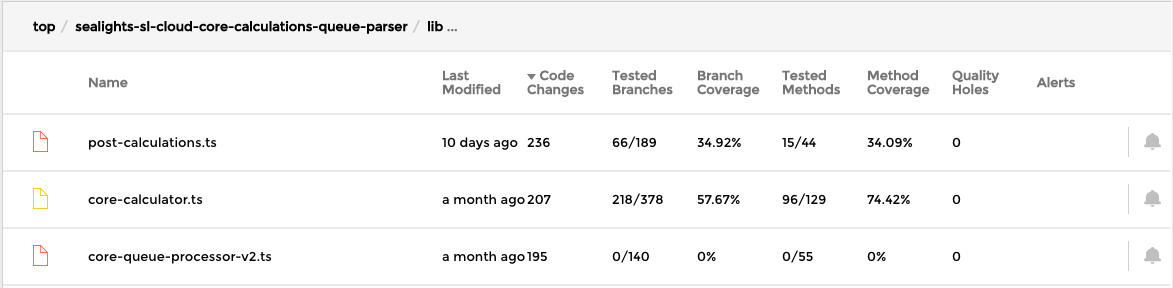
As you can see, this drill down shows that the source file: “post-calculations.ts” has highest bug risk. First, in terms of immediacy as it was modified ten days ago. Second, in terms of relevancy as it has the highest modifications recorded lately in this project (236 code-changes). Third and last, in terms of risk as it has low code coverage (34%-35%). All these insights together indicate that this candidate has the highest potential to improve quality if we invest testing efforts.
Code Quality is Key
To take quality to the next level, next generation quality metrics need to be added to your decision-making process. Holistic code coverage going beyond unit test coverage and into the higher realms of the Software Testing Pyramid and Quality Holes tracked in each in every build are the first of modern quality metrics that organizations in order to successfully achieve both speed and quality.
About the Author
Eran Sher has over 20 years experience as an entrepreneur, building emerging and high growth enterprise software companies. He is currently the Co-Founder and CEO of SeaLights, the first cloud-based, continuous testing platform. Prior to founding SeaLights, Eran co-founded Nolio (One of the first Application Release Automation platform) which was acquired by CA Technologies. Following which, Eran lead the DevOps Business Unit as VP Strategy. This article was originally published on https://www.sealights.io/blog/making-code-coverage-relevant-for-qa-teams/ and is reproduced with permission from SeaLights .